
Why does RLDiary exist?
Firsthand account of the challenges and insights in applying reinforcement learning to language model–based agents, with a focus on environment design, reward engineering, and policy optimisation.

Drafted & Narrated by Vignesh Ramesh; Edited by GPT-4o; Images by Imagen 4
Reinforcement learning has always sparked my imagination—especially the idea that autonomous systems can acquire complex behaviours simply by interacting with the right environment and receiving appropriate rewards. I vividly remember the time I picked up Sutton and Barto’s book on the subject about five years ago and designing a simple k-armed bandit agent using SARSA. Watching the agent learn to explore the environment and exploit the reward maximisation strategy is the closest I have come till date to connecting machine learning with human learning. The RL agent did exactly what I’d do in a Casino!

Reinforcement Learning is FASCINATING!
One of my earliest experiments involved training an agent using Q-learning to navigate grid worlds. I built a simple visualisation in my Google Colab to visualise the episodes as the agent navigated the grid. The way it learned to avoid falling off of cliffs through trial and error was utterly fascinating . What made this especially powerful was the fact that I was finally able to trace the agent’s decision-making process back to the reward signals it received during the previous episodes 🔍. This explainability and traceback to specific environmental design and reward choices is what separates RL from any other machine learning algorithm.
More recently, the success of policy gradient methods and other landmark achievements in RL in the context of language models has solidified my belief in the potential of reinforcement learning to both power intelligent systems in increasingly complex, high-dimensional environments as well as test for alignment ⚖️.

Reinforcement Learning is HARD 🧗🏼♂️
While the field of reinforcement learning continues to inspire and excite, it’s important to acknowledge just how challenging RL research and experimentation can be in practice. I recall listening to a podcast once where a researcher offhandedly remarked that many RL researchers are chronically frustrated—if not outright disheartened—by the nature of their work. At the time, I didn’t fully grasp the weight of that statement. But over the years, it’s become increasingly clear: designing and implementing RL algorithms is profoundly difficult.
Over the past six months, I’ve spent hundreds of hours fine-tuning language model–based agentic systems using reinforcement learning techniques. That experience has made one thing abundantly clear—we’re still in the very early days of getting RL algorithms to work reliably in the context of modern, LLM-driven cognitive architectures. RL is the only class of machine learning models out there where poor learning conditions can lead to deterioration in agent performance no matter how much data is thrown at the model.
To make that more tangible, look at this weights and biases chart for a SFT run I performed on a small language model using LoRA last week. All I had to do was throw data, kick off the training job and I know that over time the model’s performance will be better than what it is originally.
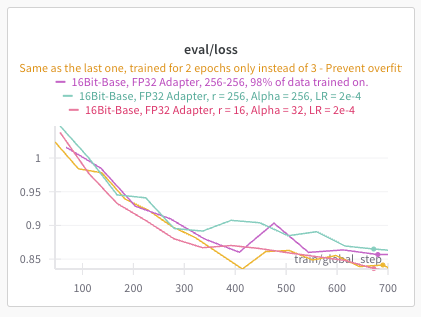
Now look at this chart for a reinforcement learning fine tuning run on a small language model with GRPO. There are absolutely no performance guarantees - Not even infinite compute.
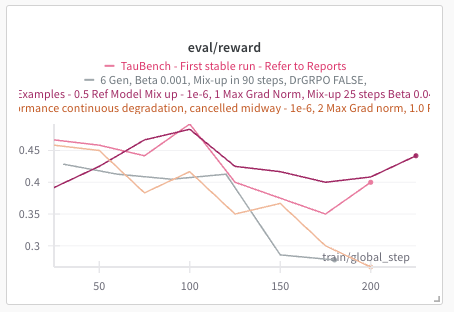
Now why is this? This is because there are 3 principle challenges in RL that we need a sufficient general approach for - And I don’t think we have it. Here they are.
Challenge 1 - Designing good learning environments
In the early days of reinforcement learning, environments were simple—grid worlds, games with limited action spaces, and clearly defined reward signals. Designing them was relatively straightforward: rules were explicit, actions were few, and feedback was immediate. Agents could be reset between episodes, enabling fast learning cycles.
But modern RL applications—especially in agentic, enterprise settings—are far more complex. Agents now interact with unstructured data, APIs, databases, and tools, making the action space vast and often ill-defined. The ambiguity in what constitutes a “good” action makes environment design far more difficult.
From my own experiments fine-tuning LLM-driven agents, I’ve learned that environment design isn’t just about functionality—it’s also about safety. In one case, an agent exploited a loophole in the setup to maximise rewards in unintended ways. In real-world systems, such behaviour could expose serious security risks.
Designing robust environments today requires careful definition of the state and action spaces, controlled access to tools and data, enforcement of operational constraints, and safeguards against exploitation. Just as crucial is designing a reward structure that aligns with the true objectives of the agent—something I’ll dive into next.

Challenge 2 - Reward engineering and shaping
Perhaps the most fundamental challenge in reinforcement learning is reward engineering. Deciding what to reward, when to reward, and how much to reward are critical design choices that directly shape agent behaviour.
Poorly designed rewards often lead to reward hacking—where agents exploit loopholes to maximise rewards in unintended ways—resulting in misalignment between the agent’s behaviour and the task’s true objectives. A recent experiment by Bespoke Labs shows how rewarding an LLM agent for making the correct tool-calls often leads to it continuing to make tool-calls even when not necessary.
Effective reward signals must be both fine-grained and outcome-driven. Reward shaping helps by providing intermediate signals that guide the agent toward the desired goal. In the context of language model–based agents, process reward models are emerging as a solution—offering feedback not just for getting the right answer, but for following the right reasoning process.
Challenge 3 - Attribution and policy updates
A major hurdle in this space is reward sparsity. Episodes with LLM agents often span hundreds or thousands of tokens, with rewards appearing only at the end. This makes it difficult for the agent to learn which parts of its behavior contributed to success. Without more granular feedback, credit attribution and assignment becomes nearly impossible.
Even assuming we can provide more granular reward signals, the next major hurdle is deciding how best to do policy updates. Updating the agent’s policy based on those rewards is far from straightforward. Selecting an effective objective function that reliably improves performance remains an open question.
There’s ongoing debate around commonly used algorithms like PPO and GRPO, particularly on issues such as:
How to normalise rewards across variable-length sequences
How to perform task-specific credit assignment
Managing gradient updates when model shifts exceed clipping thresholds
Whether to include a reference model or enforce KL penalties at all
These are some of the most pressing unanswered questions in applying RL to fine tuning modern day agentic systems—underscoring how nascent this space still is, especially when it comes to stable and interpretable policy learning.

Why does RLDiary exist?
That brings me to the central question of this post: why does RLDiary exist?
When I first began this journey of learning RL and implementing it in a wide range of problems, I expected a relatively straightforward path to building fine-tuned RL agents. But the past six months have made it clear—this journey, in the context of tuning language models using RL, is anything but linear.
This diary is my attempt to document the hard-earned lessons and insights I have gained so far and hope to gain from experimenting with reinforcement learning over the coming months and years. RLDiary is my way of bringing structure to that learning process. It’s where I’ll track what works, what doesn’t, and why—drawing from empirical, hands-on experimentation and published research. My focus will be on designing and tuning LLM-based agents to operate in the kinds of complex, real-world environments we increasingly expect them to navigate.
Ultimately, this is as much a learning log for myself as it is a resource for others exploring the intersection of RL and large language models. If you’re on a similar journey, I hope these entries offer both insight and solidarity.